Saturday, October 28, 2017
Smorms3, Softmax, and Mnist
[Research Log]
Intuitively, for neural nets, I still like the idea of features which are chosen from a set of mutually-exclusive options. E.g., if you're going to paint a picture of a fruit, typically you decide first on a kind of fruit--from a finite, known set. (This is not to dismiss the utility of continuous spaces. Consider this a didactic exercise.)
If the generative model selects downstream features independently from each other based on the upstream feature selections, then when you flip it around into an inference network (the typical mode for a supervised neural net) you can view the feature activations as being probabilities, and the weights as being log-probabilities, and then the natural activation function is softmax over each group of mutually exclusive features. (Note this also handwavingly supports some smooth interpolation, as in half way between apple and orange, but specifically avoids allowing all orange and all apple at the same time.) The usual logistic sigmoid (once favored for hidden layers) is essentially a special case of softmax for when there are just two options. (Specifically, you can turn any two-node softmax group into a single logistic node by setting the logistic node's weight vector to the difference of the two softmax weight vectors, and then that logistic node will behave exactly as one of the softmax nodes--which one depends on which way you do the subtraction.)
Now days, softmax is typically used only on the output layer. A quick search for its application in hidden layers turned up mostly discussions about why it's a bad idea. So naturally I had to try it.
Seemed like a good excuse to try Tensorflow so I started from the deep mnist tutorial and just tweaked the relu on both convolutional layers to be tf.nn.softmax instead. Note that by default tf softmax normalizes over the last index, which in this case means normalizing over all convolutional filters at a given location. I.e., we're treating the filters as a mutually exclusive set of features (per location), as opposed to relu which allows arbitrarily many of them to be active at once. (On the second convolutional layer, this means treating all 64 features as one mutually exclusive set. I should probably try breaking that into two or more smaller groups but not sure how I'd visualize the consequence so I'm punting on that for now.)
As a side note, I got impatient waiting for it to train, so did a quick search to see if anybody had implemented SMORMS3 in Tensorflow yet, which indeed someone has, so I took five minutes to plug that in (with no tuning or tweaking whatsoever) and it trains at least twice as fast as Adam which the tutorial uses. (It does start off a bit violently, though--might need to add some sort of gentle easing-in phase at startup to be generally safe, but whatever, it still works.)
The net result of the relu/softmax change was basically nil in terms of performance (both got ~99.3%). However, I think the lowest level features (which are the only ones trivial to plot) are much prettier in the softmax case--take a look:

Features trained with ReLU activation function
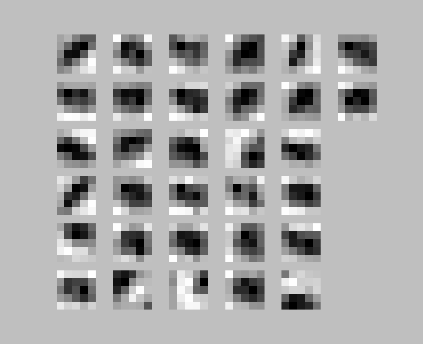
Features trained with Softmax activation function