Monday, April 20, 2015
RMSprop loses to SMORMS3 - Beware the Epsilon!
Another Technical Report on stochastic gradient descent of little interest to non-AI-nerds.
Follow-up to this.
I tried Adam, but it wasn't doing nearly as well as RMSprop. After some investigation, it turns out RMSprop was relying heavily on the 10^-6 epsilon, which due to being inside the sqrt was acting more like a 10^-3 damping term. After setting Adam's epsilon to 10^-3 it did about as well as RMSprop. All I can say is: yuck.
Once I understood that RMSprop was in some sense cheating, I gave a fresh look at my wince-inducing hybrid, which I've since renamed SMORMS3 for squared mean over root mean squared cubed.
SMORMS3 is a hybrid of RMSprop, which is perhaps trying to estimate a safe and optimal distance based on curvature or perhaps just normalizing the stepsize in the parameter space, and part of LeCun's method, which is choosing a learning rate based on how noisy the gradient is. It's probably more fair to say SMORMS3 is just a poor man's version of LeCun's method, for people too lazy to cook up a better Hessian estimate.
I'd come up with the same denoising idea before, but LeCun has a nice proof for it. My intuitive reasons were simple: First, as you get closer to home, your mean gradient approaches zero but the noise may not, and that's when you need to take smaller steps so you can narrow in. Second, the variance of the gradient (if it's roughly normally distributed) is going to vary linearly with with the inverse of the batch size (whereas the mean gradient should be roughly independent of batch size), which means the inverse variance is a natural automated batch-size normalizing constant. One would hope that the same ratio has the further property of selecting a nice rate based on the noise inherent to the system (rather than just relative to batch size), and LeCun I believe shows that to be true.
Running with the "care about parameter space" idea from last time, I put the "learning rate" in as a minimum against the denoising factor rather than a product. Call this damping if you like, or just view it as a parallel constraint. I prefer having it here instead of, say, using epsilon, because it keeps it in the (known) scale of the parameters themselves rather than in the (relatively unknown) scale of the gradients. Empirically it also worked best this way, but I didn't do a lot of trials. That parameter (call it the max learning rate) is now the only one of relevance (there is an epsilon left but it's just to protect against divide by zeros), and it can probably stay the same for a given style of parameter over a variety of contexts. (It can be provided as a scalar, or a per-parameter vector, if, say, we know certain parameters have a completely different range than others.) So, not completely tweak-free, but closer.
The SMORMS3 algorithm goes like this:
Initialize:
mem = <1> # Vector of 1's, same shape as p
g = <0> # Vector of 0's, same shape as p
g2 = <0>
Given cost function cost(p), and some trivial epsilon (1e-16), take one step per mini-batch as follows:
grad = gradient(cost, p) # Gradient of cost(p) with respect to p
r = 1/(mem+1)
g = (1-r) * g + r * grad
g2 = (1-r) * g2 + r * grad ** 2
p = p - grad*min(lrate, g*g/(g2 + epsilon))/(sqrt(g2)+epsilon)
mem = 1 + mem*(1 - g*g/(g2 + epsilon))
(Where products, divides, and min are element-wise.)
Here's a plot of various runs (with log-cost on Y, log-epochs on X):
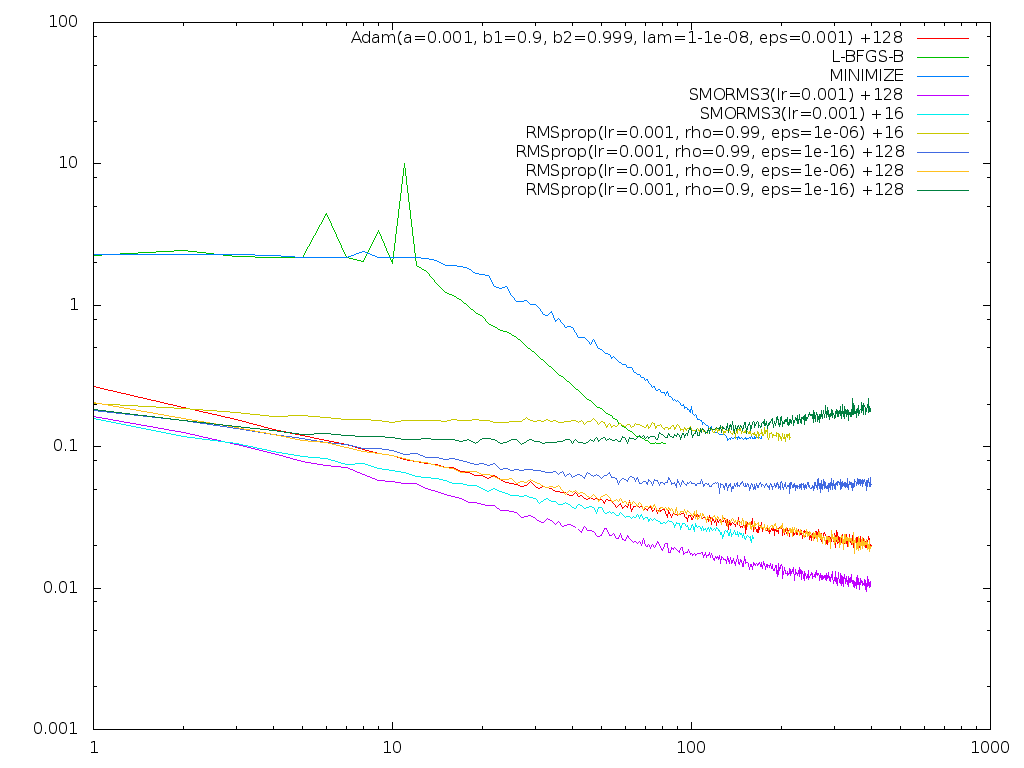
These are all with dropout. Notice in particular how sensitive RMSprop is to parameter choices, and to mini-batch size which is shown as the + number on the right. (SMORMS3 at mini-batch size 16 stops where it does because my machine crashed...) SMORMS3 handled a ~x10 mini-batch size change with no re-tuning reasonably well. RMSprop did not. Adam was similarly sensitive, though not as much so as RMSprop. I did try RMSprop with rho=0.999 on the +16 case, but it didn't help. After playing with both Adam and RMSprop more, I don't feel I can trust either to "just work" without tuning. I will need to try some qualitatively different problems before I know how I feel about SMORMS3. It may fall flat on networks with uglier curvature. And I'm not thrilled it does any worse with the smaller mini-batch size. It was working so-so at mini-batch size 1 (still not bad but not great) but that also died during the crash. I will be happy when I have something that works as well (or better) at mini-batch size 1 as at 1000 with no tuning.
If anybody plugs SMORMS3 in to their problem, please let me know how it does.